
By Alfredo Cely, P.E., PMP, M.ASCE, and Leo Guim, P.E.
In the architecture, engineering, and construction industry, practitioners depend on ever-evolving technical standards and guidelines to manage and execute infrastructure projects. These crucial documents, which frequently reference other technical materials, are updated on varying schedules — some annually and others less predictably. This inconsistency complicates the task of staying informed about the latest guidelines.
Additionally, a bias toward past knowledge often influences a practitioner’s decision-making. It is common to hear phrases like “This is how we solved this issue on the last project” or “We have always approached this problem this way.” These attitudes and challenges underline the need for an innovative tool that enables practitioners to seamlessly negotiate the most current criteria in a truly up-to-date, integrative manner.
Natural language processing — a form of artificial intelligence — is revolutionizing how we interact with complex information, and by harnessing the power of large language models (another form of AI), we can now transform large volumes of text into interconnected references, a significant departure from traditional keyword searches. These models transform searches into guided navigation of complex document libraries via sophisticated pattern recognition that identifies relevant content in response to user inquiries. Plus, these document navigational guides smoothly integrate with conversational AI technologies, such as chatbots, which interpret the questions and deliver answers in understandable human language.
This powerful combination of AI technologies not only accelerates the process of accessing information, but it also empowers users to interact with engineering technical documents as if conversing with a knowledgeable assistant. It makes the complex material more user-friendly, enabling practitioners to search it quickly and efficiently, thereby instilling a sense of confidence and capability in their work.
AlfKa, an engineering services firm, manages statewide training programs for the Florida Department of Transportation and other state agencies in Florida. During the management of these programs, a need was identified for an AI tool to help users effectively review and understand technical guidelines and manuals. To address this, AlfKa initiated a three-month pilot project to evaluate the application of new AI tools for navigating complex, cross-referenced technical guidelines.
The case study used the Florida Department of Transportation (FDOT) Design Manual as a template to create a technical agent the project team named the FDM Navigator. The FDM is the guiding technical document FDOT uses to design all projects — construction, reconstruction, and resurfacing — on its state highway and national highway systems.
The FDM was chosen because its many chapters and subsections cross-reference each other. It has three main sections, each with multiple chapters that are cross-referenced with FDOT’s Standard Plans for Road and Bridge Construction and Standard Specifications for Road and Bridge Construction. These three documents function as the cornerstone for the design of Florida’s state highways. Figure 1 below shows how the three manuals reference each other.
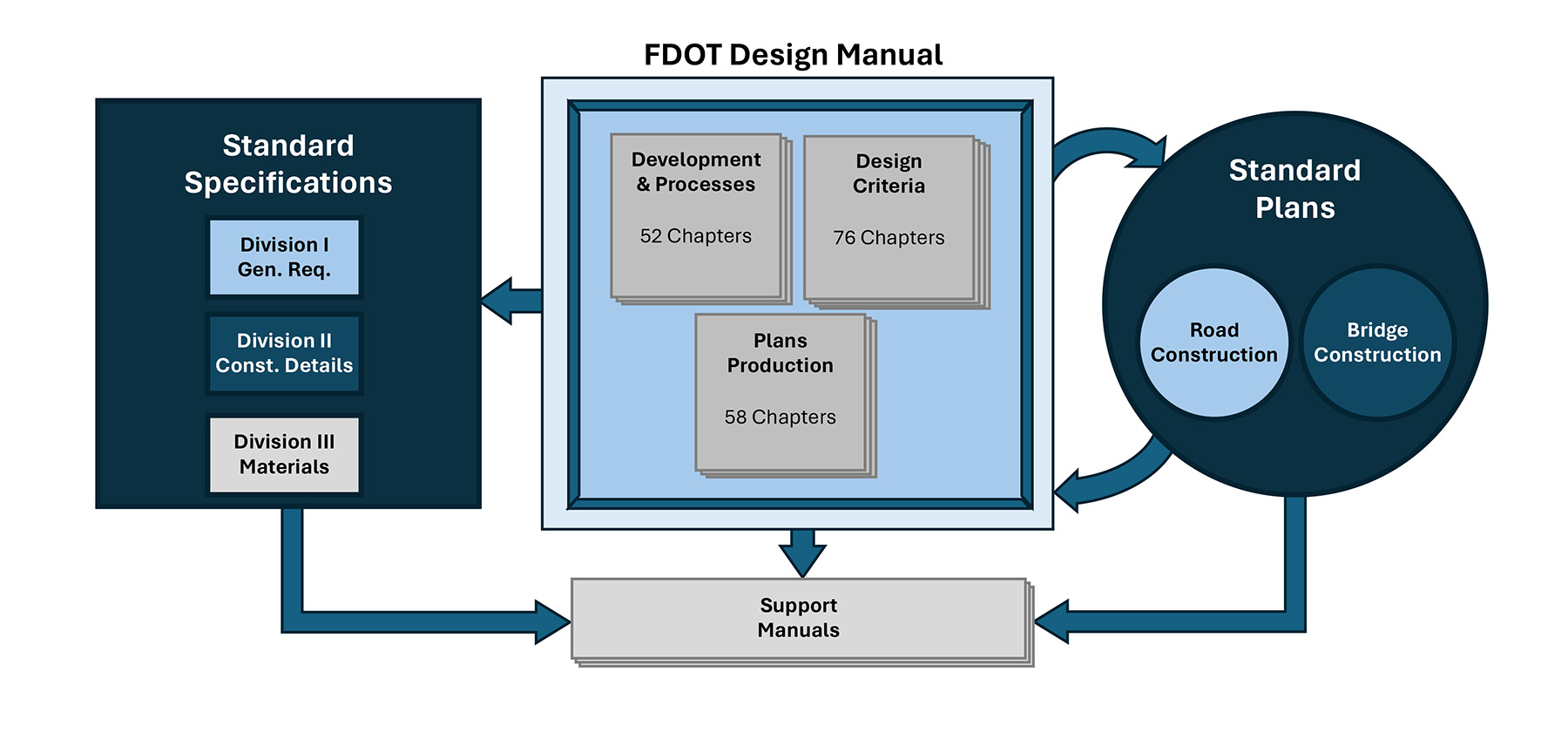
For the pilot project, our efforts were focused on creating a technical agent limited to finding answers within the 2024 edition of the manual. Once fully developed, the Navigator’s user-friendly conversational interface could be expanded to include standard plans and standard specifications documents, as well as a multitude of support manuals, giving it a broader scope and allowing practitioners to have a holistic evaluation of all the guiding technical documents.
Define goal, scope, and function
The first step in creating the technical agent was to define a clear goal and scope. The main goal was to provide users with prompt access to the FDM using an interactive and user-friendly, conversational interface. The next step in the development was to limit the scope of the application to ensure it would function within the parameters of technical information included in the manual.
The team began by cross-referencing the manual’s three main sections — Development and Processes, Design Criteria, and Plans Production — within the underlying database. Limiting responses to questions made within these three main elements directed the FDM Navigator to a specific body of knowledge and self-enforced the tool to respond to questions limited to the FDM. To help limit the scope, the team developed a set of classification parameters to clarify the types of questions the tool could answer. For this pilot project, these limiting guardrails were implemented by categorizing the types of incoming questions to help funnel the formulation of answers.
The project team developed a classification system to direct user queries into four initial categories: development and processes questions, design criteria questions, plans production questions, and general integrative design questions. There is an implicit fifth category, the “I don’t know the answer” bin. Thus, when receiving questions, if the agent could not find a proper classification with a degree of statistical certainty, it would provide a response requesting a more detailed question or state that it could only answer questions about the technical content of the FDM.
Data collection and processing
The development of the underpinning database began with classifying the information within the FDM into categories such as text, figures, and tables, and then vectorizing these data for ease of integration. The FDM’s native standardization and classification of data simplified the effort of creating semantic data vectors. This initial categorization facilitated cross-referencing within the manual, allowing for seamless connections between different sections, figures, and tables.
Following this initial standardization, a comprehensive review identified references to external content. The database was then updated to include four distinct types of information: text, images, tables, and external references. The final stage of data processing involved creating embeddings for each item. These embeddings, which are quantitative representations that capture semantic meanings, are organized within a high-dimensional vector space to bring similar content closer together.
The embedding of content is the main engine behind AI models. This sophisticated arrangement transforms the database into a vector store, enabling semantic searches and the retrieval of relevant information that is closely connected.
Because the FDM, like other engineering manuals, undergoes regular updates, it is necessary that the tool’s structure be easily updatable. The structure includes section and subsection numbers to help identify each piece of information. Making revisions to the manual in the future can be as simple as updating specific sections. The use of different manual editions enables the FDM Navigator to create an update history. Historical information can help users locate recent changes in criteria or evaluate criteria used for past projects.
Model training and workflows
Preprocessing the data to optimize their structure for use with conversational AI applications improved the Navigator’s efficiency. This process optimized the content by synthesizing text into its core informational elements, removing redundancies and ligatures, and tokenizing text content to speed up retrieval. Tokenizing — splitting sentences into individual words and converting these words into individual tokens — is a key element in helping the model create the statistical connections between words, sentences, and technical meaning within the analyzed content. This dataset refinement improved the agent’s response accuracy and the quality of its interaction with users. Figure 2 shows a depiction of the model network created by tokenizing words, images, and links within the technical manual.
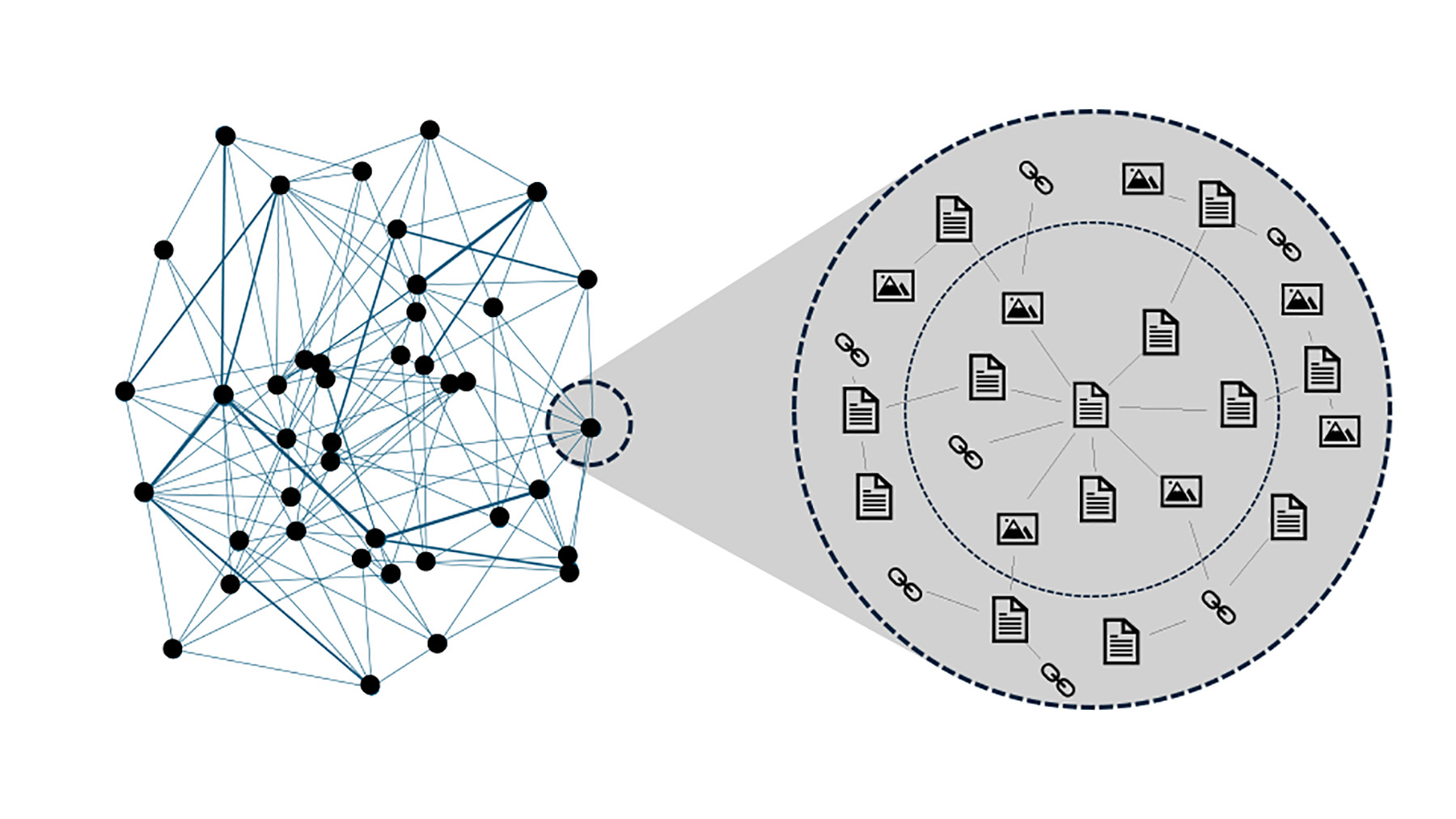
As with any technical manual, the FDM has a set of particular terminologies that are solely used within the context of the manual and its main technical purpose. Even though conversational AI agents have been trained on large volumes of general texts, the specificity of the FDM easily escapes them. Thus, an additional layer of model training was necessary to fine-tune the technical agent to the specifics of the manual’s terminology.
A dataset of technical questions and answers was created to generate multiple questions and their respective answers to help train the Navigator on the terminology used within the manual. Sections of the FDM, like its glossary, were used as part of this training element to ensure the technical agent was exposed to terminology used explicitly within the context of the design manual.
Developing the FDM Navigator involved setting up a back end that could handle diverse user requests, manage the flow of conversation, and generate relevant and contextually appropriate responses by implementing intent recognition. A conversational workflow was developed to guide the technical agent in recognizing user intent. Interactions could span multiple exchanges, building context around the user’s questions and helping the Navigator better classify and tailor its responses.
The Navigator follows a three-step workflow when responding to user queries. First, the technical agent must classify the incoming question into one of the five categories shown in Figure 3. Then, based on its classification, it must provide a response that meets the answer criteria predefined for each question category. And as a third step, it uses the embeddings within the database to find the information that best fits the user’s request.
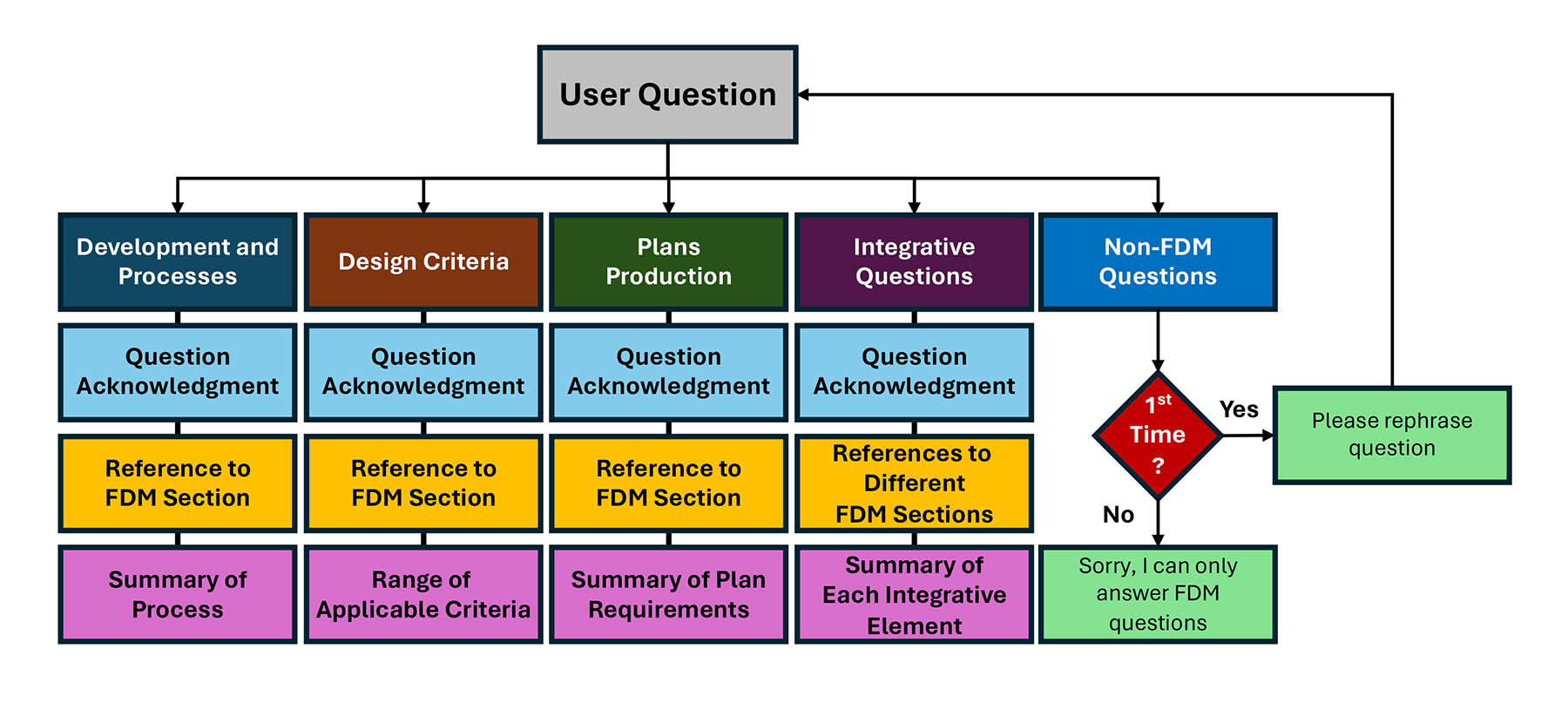
Figure 4 is an example of a model response. It highlights each of the answer components noted in the workflow and provides a graphical representation of how the answer was obtained from the specific FDM section.

The tool first classifies the user question into the Plans Production category. From there, it searches for the section most relevant to the question based on the embeddings of the vector database. In this case, it falls under Section 921.7, Detour Plan Sheets. The technical agent references that section of the FDM and provides a hyperlink to that section. Then, it gives the answer.
The NLP model focuses on optimizing responses in a manner similar to creating a summary of an idea. This is evident in the response above, as the model creates a brief summary of FDM Section 921.7 to answer the prompt question. In this example, the information shown on the detour plan will vary depending on the project being designed; thus, a practitioner must use professional judgment to identify how the information applies to the specific project. This is the same as when a professional uses a manual or guideline; the same professional judgment must be exercised to properly apply the criteria to the specific project.
Testing and deployment
A principal piece of the final testing of the technical agent was the inclusion of common guardrails against misuse or user abuse, such as hate speech or misinformation. Implementing these safeguards is straightforward, thanks to widely available datasets from public conversational AI agents that provide information on managing adverse content.
The deployment of the FDM Navigator is similar to the deployment of other IT-based engineering support tools, where the technical tool is only available to registered users. The registered-user system has the added benefit of allowing traceability of user queries. This can provide further information to improve the underlying technical agent and its database, as well as offer insights for improving the underlying manuals and guidelines.
The benefits
Using conversational AI agents supported by large language models can significantly benefit practitioners and technical manual owners. Based on this short-term (three-month) pilot project, some of the following benefits for users and owners have been identified.
Enhanced cross-disciplinary insights: The Navigator helps users discover connections to technical areas outside their primary expertise, offering a broader integrative context for more informed decision-making.
Accelerated learning curve: Ideal for new practitioners, the tool reduces the learning curve associated with understanding comprehensive technical manuals, enabling quicker adaptation to new jurisdictions.
Historical data navigation: The tool facilitates access to older versions of technical manuals, allowing professionals to effectively compare changes and assess past projects, which is critical in environments in which design criteria are continually evolving.
Enhanced planning and predictive analytics: Data from user interactions can be used for predictive analytics, suggesting modifications to the design manual based on recognized patterns. This helps change the process of updating design manuals from just passing updates to the audience, to updating manuals based on receiving feedback from the audience.
Streamlined manual updates: The vectorized database clarifies the interconnections affected by updates, enabling manual owners to more effectively implement changes and ensure comprehensive updates across all integrated areas.
Reduction in information requests: By automatically addressing common questions, the tool minimizes the need for manual intervention by technical staff, reducing the workload and improving efficiency.
Scalability: Owners can expand the tool’s capabilities by adding more information, thereby continuously enlarging their knowledge base and enhancing the integration of various processes and standards within an organization.
Future implications
AI tools like the FDM Navigator can be integrated with engineering software, making design software highly customized to the respective needs of different agencies. These tools can serve as an initial quality control layer within engineering design software. What’s more, these tools can take a first pass and flag items that may not be within the current criteria; they can help practitioners quickly navigate ever-increasing amounts of technical data; and most importantly, they can create connections among related technical criteria.
It is important to emphasize that even though these tools can help expedite the processing of technical information, the decision on selecting how to apply technical criteria to specific engineering projects will always depend on a professional’s judgment.
Alfredo Cely, P.E., PMP, M.ASCE, is president of and Leo Guim, P.E., is a chief engineer at AlfKa in Tampa, Florida.
This article first appeared in the July/August 2024 issue of Civil Engineering as “Building with Words: Applying Natural Language Processing in Civil Engineering.”
Want to know more about this topic? Join the authors for a free webinar on Fri., Aug. 16 at 3:00 p.m. ET.

